Ceci est un rouleau de papyrus:

Il a vécu des jours meilleurs. Il faut dire qu’il a été déterré au dix-huitième siècle, 1700 ans après avoir été recouvert de cendres et de débris, et complètement carbonisé, lors de l’éruption du Vésuve. Avant ça, il se trouvait dans une belle villa d’Herculaneum, bien installé dans une bibliothèque avec plusieurs centaines de ses camarades. Les historiens aimeraient beaucoup pouvoir lire ce qu’il y a dans ce papyrus, et dans les centaines d’autres récupérés dans la villa. Mais comment faire pour lire un manuscrit carbonisé et impossible à dérouler sans complètement le détruire ?
C’est à cela que s’attaquent celles et ceux qui participent au “Vesuvius Challenge”, et c’est pas de la tarte ! Mais les premières lettres ont récemment été déchiffrées, ce qui laisse à espérer qu’une solution plus ou moins complète est au moins possible. Pour arriver à faire ça, les rouleaux ont été imagés avec un CT scan à haute résolution (8µm par pixel), ce qui permet de “voir” à l’intérieur. Plus ou moins – c’est un peu plus compliqué que ça.
Il y a trois étapes principales pour résoudre le problème:
- Dérouler virtuellement le manuscrit pour retrouver des fragments plus ou moins intacts
- Retrouver sur ces fragments déroulés des traces d’encre
- Lire
Dérouler virtuellement le manuscrit
Une coupe transversale du rouleau ressemble à ça (toutes les images proviennent de scrollprize.org):

Si vous voulez voyager à travers les coupes, il y a une vidéo de 8 minutes qui traverse tout le rouleau: https://www.youtube.com/watch?v=cY5BIxkf5m0&t=33s.
On peut assez clairement voir les différentes “couches” du rouleau. Mais pour les “dérouler”, il ne suffit pas de “clairement” voir, il faut faire voir à la machine. Ce qui signifie, pour l’instant en tout cas, de manuellement venir annoter les images pour “suivre” le trajet du parchemin, à travers les couches, jusqu’à ce qu’on ait un fragment de taille raisonnable pour lequel on est sûr d’avoir bien identifié le papyrus. On peut ensuite simuler le “déroulement” de ce fragment pour obtenir un volume aplati. Ici, on voit ce que ça donne:

On y voit assez facilement la texture des fibres du papyrus. Par contre, pour lire, c’est un peu plus compliqué.
Retrouver des traces d’encre
Une technique similaire avait été utilisée pour déchiffrer certains manuscrits de la mer morte. Mais pour ces manuscrits, l’encre utilisée avait des composants métalliques, qui la rendait fort visible au CT. L’encre utilisée à Herculaneum, malheureusement, n’a pas cette propriété: elle est invisible aux rayons X.
Ou plutôt, presque invisible.

Casey Handmer, un participant du concours, a gagné $10.000 grâce à cette découverte: vous voyez ces petites craquelures sur le papyrus ? Non ?

Et là ? Les craquelures sont, probablement, des résidus d’encre. Ils forment ici la lettre pi: le manuscrit est en grec.
Luke Farritor et Youssef Nader ont ensuite indépendamment entraîné des modèles de machine learning à reconnaître ces résidus d’encre, afin de générer des images ‘améliorées’, où les lettres deviennent visible à l’oeil nu. En tout cas: plus visibles.
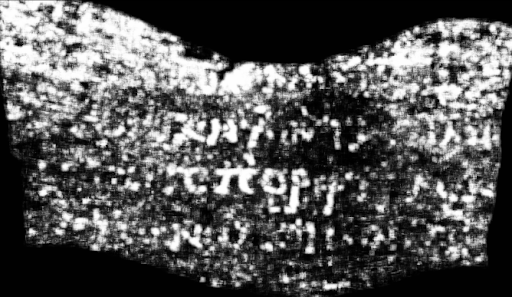
Une fois le premier mot trouvé, les choses s’accélèrent, les modèles s’améliorent, et les images aussi:

Problème résolu?
Y a plus qu’à…
On sait maintenant qu’il est possible de dérouler virtuellement le manuscrit… en tout cas certains morceaux.
On sait qu’il est possible d’y trouver des résidus d’encre, et de les mettre en avant.
Mais le boulot reste conséquent. Pour l’instant, la “segmentation” des fragments de manuscrit (c’est-à-dire: séparer les couches du rouleau et en faire des morceaux de taille suffisante pour en tirer potentiellement du texte) est en bonne partie manuelle, et donc lente. Des outils pour accélérer et partiellement automatiser le processus sont en train d’être construits, avec plus ou moins de succès. Et en identifiant et déroulant les fragments, il faut évidemment faire attention à prendre note de sa position dans le rouleau initial, le but étant in fine de pouvoir recréer un manuscrit complet.
Quand à la lecture, on sait que le modèle fonctionne sur certains fragments. Mais il est encore trop tôt pour dire s’il fonctionnera sur l’ensemble du rouleau. Peut-être que d’autres couches, ou d’autres régions du rouleau, auront des propriétés légèrement différentes. Et les indices permettant de détecter l’encre sont tellement subtils qu’il suffirait de pas grand-chose pour que le modèle soit à nouveau perdu.
Mais aujourd’hui, il semble assez probable qu’on finira par y arriver, et dans pas trop longtemps. Et qu’on pourra enfin découvrir le contenu de cette bibliothèque enfouie, et peut-être mettre la main sur des textes perdus depuis prêt de 2000 ans.
Il y a en tout cas une certaine motivation pour les chercheurs sur le coup: l’équipe qui arrivera à déchiffrer quatre passages séparés d’au moins 140 caractères successifs dans les deux rouleaux imagés avant le 31 décembre 2023 remportera $700.000.